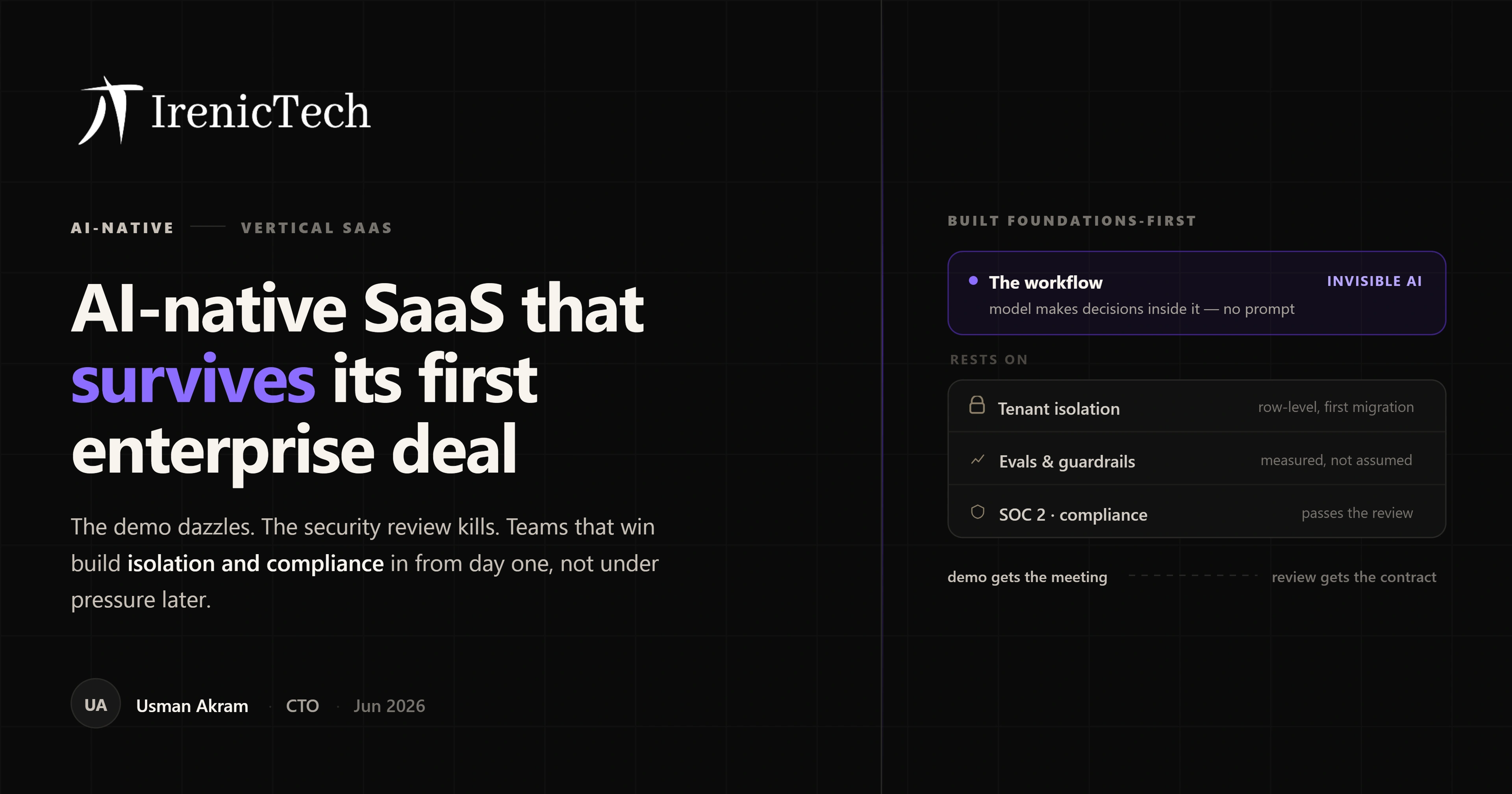
Most AI Agents Never Reach Production. Here's What Separates the Ones That Do
Pilots are easy; production is where AI agents go to die. Here's why most never make it, and the unglamorous engineering, evals, guardrails, feedback loops, that separates the agents that ship from the ones that stall.
Usman Akram · · 3 min read
Nobody's really arguing about whether enterprises want AI agents anymore. The average company is already running about a dozen of them, GitHub Copilot by itself serves 20 million users across 90% of the Fortune 100, and Gartner figures 40% of enterprise apps will have task-specific agents baked in by the end of 2026. And yet most of the agents teams build never turn into something they actually rely on in production. That gap, between an agent that wows in a demo and one you'd trust on a Tuesday with nobody watching, is where all the real work hides.
Why do most AI agents stall before production?
The honest reason is almost never "the model wasn't smart enough." Agents get stuck for dull, fixable reasons. Nobody built a way to measure whether the agent is actually right, so nobody can quite bring themselves to trust it. There are no guardrails, so a single bad action is one too many to risk. There's no feedback loop, so a mistake today is the same mistake next month. And it's been handed far more access than its job calls for, which means it can't be turned loose safely even when it works.
The numbers back this up. One 2026 industry report found that enterprises run about 12 agents on average, but roughly half of them are off in a corner working alone, never plugged into the workflows that would make them worth anything. Plenty of pilots. Not many graduates.
The demo-to-production gap
A demo proves an agent can get it right once, on a tidy example, with a human hovering nearby. Production asks it to get things right over and over, on messy real inputs, with nobody hovering at all. Those aren't the same engineering problem, and the second one is the one teams routinely underestimate.
We've watched this play out: a client's old tool was "right most of the time," which sounds fine until you're checking a medical protocol and a single wrong answer costs you all their trust. We told that story in full; the short version is the tool wasn't dumb, it just had no way to show it was right or to learn when it wasn't.
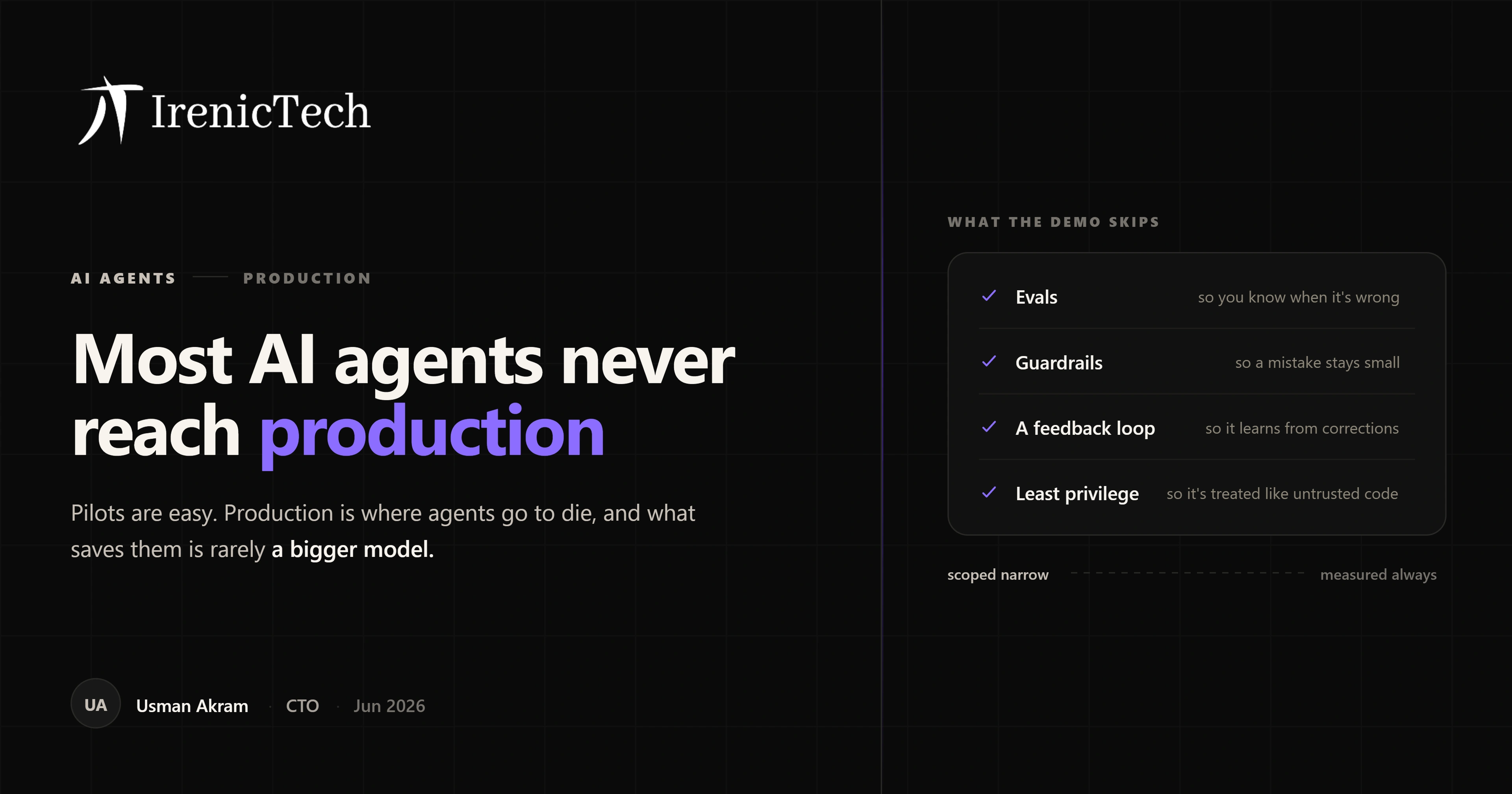
What a production-ready agent actually needs
Four things, and they're usually the four the demo quietly skipped:
- Evals, so "it works" is an actual number measured on real tasks instead of a feeling.
- Guardrails, so when the agent does get something wrong, the blast radius stays small.
- A feedback loop, meaning a way to flag bad answers and feed the corrections back in. On one system we built, that alone moved accuracy from somewhere around 80% to close to 95% over a couple of months, without ever swapping the model.
- Least-privilege access, so the agent has exactly what the task needs, monitored and allow-listed, and nothing else.
Notice what isn't on that list: a bigger model. Most teams reach for a fancier one when what they were actually missing was the unglamorous plumbing around it. Build the feedback loop first. Worry about the fancy model second, if at all.
Scoped narrow, measured always, trusted carefully
The agents that make it to production tend to look alike. They're pointed at one narrow, useful job instead of some open-ended "handle everything" brief that drifts for months. They're measured constantly, so you can see accuracy and watch it climb. And they're handled like untrusted code, kept isolated and least-privileged and watched, so they take work off people's plates without becoming the weakest link in the stack.
That's the thinking behind how we ship AI products in weeks, not quarters, and it's the heart of our AI Native practice: pick one slice, build the evals and guardrails before you add capability, wire in the feedback loop, and get it in front of real users early. An agent that ships in weeks, proves it's right, and earns the trust to touch real data tells you something a demo never can.
Got an agent that's been stuck at the pilot stage? Let's get it to production.
Frequently asked
Why do most AI agents fail to reach production?
Not because the model isn't capable, but because the engineering around it is missing. Agents stall when there are no evals to measure whether they're right, no guardrails to contain mistakes, no feedback loop to improve them, and too much privilege to operate safely. A demo proves an agent can work once; production demands it work reliably every time.
What does an AI agent need to be production-ready?
Four things the demo usually skips: evaluations that measure accuracy on real tasks, guardrails that constrain what the agent can do, a feedback loop that turns mistakes into improvements, and least-privilege access so it can't reach systems it shouldn't. Together these turn a clever prototype into a system you can trust in production.
How long does it take to get an AI agent into production?
When it's scoped to one narrow, useful job rather than an open-ended 'do everything' agent, a first production release is a matter of weeks. We ship that slice to real users, measure it, and expand from there instead of chasing a perfect agent that never launches.
How does IrenicTech build production-ready AI agents?
We scope the agent narrow, build evals and guardrails before adding capability, wire in a correction feedback loop so it improves with real use, and treat it like untrusted code with isolated, least-privilege, monitored access. That's how an agent ships in weeks and keeps working instead of getting abandoned.
CTO, IrenicTech
Usman is the CTO of IrenicTech. He builds AI agents, RAG systems, and automations into web and mobile products, and gets them shipped in weeks instead of quarters. He's focused on AI that learns from the people using it, and that's secure enough to trust with real data.
Connect on LinkedIn